Python에는 데이터 분석을 도와주는 패키지가 있습니다. 제일 많이 사용되는 3가지가 있는데 오늘은 이 3가지에 대해서 알아보도록 하겠습니다.
Python에 데이터 분석을 도와주는 대표적인 패키지는 Numpy, Pandas, Matplotlib 이렇게 총 3가지가 대표적인 패키지입니다.
Pandas는 RDBMS(관계형 데이터베이스)를 다루기 위해서 사용하는 패키지입니다. 행과 열로 구성된 RDBMS는 Python에서 DataFrame이라 부릅니다.
numpy는 벡터형 데이터와 matrix를 다루기 위해서 사용하는 패키지입니다.
matlibplot은 데이터를 시각화하기 위해 사용되는 패키지입니다.
패키지를 사용하기 위해선 설치를 해야합니다. 아래와 같이 입력하고 실행하면 설치가 가능합니다.
pip install pandas
pip install numpy
pip install matplotliba = 1
b = 'hello'이처럼 하나의 값을 가진 변수를 '스칼라'라고 부릅니다.
a = [1, 2, 3]
b = ['hello', 'world']이처럼 여러 값을 가진 변수를 '벡터'라 부릅니다. 참고로 데이터 분석은 이런 '벡터'를 다룹니다. DataFrame의 변수도 결국 '벡터'입니다. 이러한 '벡터'를 pandas에선 Series라고 부르고 numpy에선 ndarray라 부릅니다. (참고로 행과 열로 나누는 테이블 데이터 속 통계에서는 열을 변수, 행을 관측치라고 부릅니다)
# Python에서 제공하는 벡터를 다루는 몇 가지 함수
all([1, 1, 1]) # 벡터 데이터 모두 True면 True를 반환
any([1, 0, 0]) # 한 개라도 True면 True 반환
max([1, 2, 3]) # 가장 큰 값을 반환
min([1, 2, 3]) # 가장 작은 값을 반환
list(range(10)) # 0부터 10까지 순열을 만듦
list(range(3, 6)) # 3부터 5까지 순열을 만듦
list(range(1, 6, 2)) # 1부터 6까지 2단위로 순열을 만듦벡터 요소에 대해 검사하고 결괏값을 반환하는 함수들입니다. 데이터 분석을 위해선 위 함수 외에도 평균, 분산 등을 구할 함수가 필요한데, 이런 함수들은 numpy, pandas가 제공합니다.
우선 Sample로 사용할 Data를 가져옵시다. (Kaggle의 Titanic test csv 파일을 사용했습니다)
Pandas
import pandas as pd
df = pd.read_csv("input/input.csv")
df.head()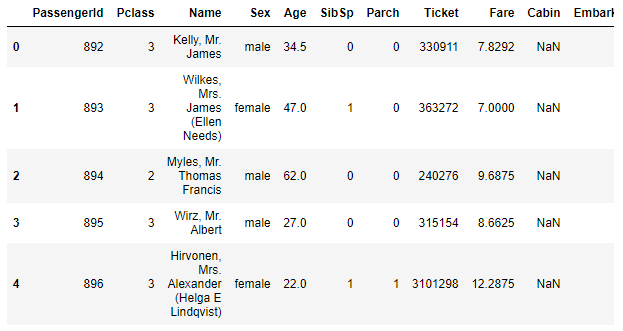
head() 함수는 데이터의 맨 앞부분 5개를 보여줍니다. 반대로 df.tail()는 데이터의 뒷부분 5개를 보여줍니다.
df.tail()
만약 특정 범위의 관측치만 보고 싶다면 행에 대해 슬라이싱 하면 됩니다.
df[0:2]
변수명만 따로 살펴보도록 합시다.
df.columns
columns라는 속성에 모든 변수가 저장되어 있습니다. 이제 데이터의 여러 통계 정보를 살펴봅시다.
df.describe()
각 변수에 해당하는 count(관측치 값), mean(평균), std(표준편차), min(최솟값), max(최댓값)을 알려줍니다. 25%, 50%, 75%는 데이터 4등분하여 25%에 해당하는 값과 50%, 75%에 해당하는 값을 나타냅니다. 물론 평균, 표준편차 등을 알려주는 함수는 별도로 있습니다. 평균을 구하려면
df.mean()
변수별로 평균만 나타난 것을 볼 수 있습니다. (물론 위 데이터 중에 categorical data가 포함되어 있기 때문에 평균이 의미가 없는 columns도 있는 것을 알고 넘어가야 합니다)
pandas에서는 특정 변수를 기준으로 그룹을 지어 통계값을 구할 수도 있습니다. 예를들어 "Pclass" 변수별로 "Fare"의 평균 값"을 구하는 코드는 아래와 같습니다.
df.groupby(['Pclass']).mean()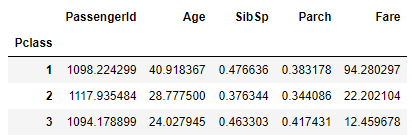
"Pclass"는 선실 등급인데 1등급, 2등급, 3등급인 경우에 해당하는 평균을 각각 알려줬습니다. "Fare" 변수에 대해서만 선실 별로 평균값을 구하고 싶다면 다음과 같이 합니다.
df.groupby(['Pclass'])['Fare'].mean()
결국, 위 코드는 "선실 클래스 별로 Fare의 평균"을 구한 것입니다.
이처럼 그룹을 지을 수도 있고 변수를 선택할 수도 있습니다. 만약 단순히 특정 변수를 선택해 평균을 구하고 싶다면 다음과 같이 하면 됩니다.
df['hp'].mean()
변수를 선택하는 여러 방법이 있습니다.
df.Age
df['Age']
두 방법의 결과는 같으니 편하신 것을 사용하시면 됩니다. 또한 변수 안에서 슬라이싱이 가능합니다.
df.Age[15]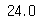
또한, 여러 값을 슬라이싱 가능합니다.
df.Age[0:14]
변수만 선택했을 때 자료형이 무엇인지를 확인할 수 있습니다.
type(df.Age)
Series라고 알려줍니다. 통계적 의미에선 변수이지만 pandas는 Series라 부릅니다. Pandas의 DataFrame은 이 Series의 모음입니다. 지금부터 Age 변수만 따로 저장해서 Series에 대해 자세히 살펴보도록 합시다.
a = df.Age
aSeries는 크게 index와 value로 나눕니다.

여기서 왼쪽이 index이고 오른쪽이 value입니다. index는 아무 조치를 하지 않으면 0부터 시작합니다. 또, Name이란 value를 a의 index로 넣어봅시다.
a.index = df.Name
a
이제 이름으로 value 값을 접근할 수 있습니다.
a['Wirz, Mr. Albert']
슬라이싱도 가능합니다.
a['Wirz, Mr. Albert':'Peter, Master. Michael J']
이렇게 만들어진 Series는 연산도 가능합니다.
print(a*2)
pandas의 series의 통계 값을 구하는 함수를 정리하면 다음과 같습니다.
df.Age.mean() # 평균
df.Age.std() # 표준편차
df.Age.var() # 분산numpy
Series는 벡터입니다. 이 벡터를 pandas에선 series라 부르지만 numpy에선 ndarray라 부릅니다. 두 패키지 모두 벡터를 다루지만 사용 용도가 다릅니다.
import numpy as np
np.mean(df.age) # numpy로 평균 구하기
np.std(df.age) # numpy로 표준편차 구하기
np.var(df.age) # numpy로 분산 구하기pandas의 series는 numpy에서 모두 인식됩니다. 벡터는 다음과 같이 일차원입니다.
{0, 1, 2, 3, 4, 5, 6, 7}
다음은 이차원 매트릭스 입니다.
([0, 1, 2, 3], [4, 5, 6, 7])
numpy는 다차원 구조를 가진 데이터를 처리하기 위한 용도로 만들어졌습니다. 삼차원을 넘어 다차원까지도 처리가 가능합니다. DataFrame과 Matrix는 비슷해 보이지만 차이가 있습니다. Matrix는 수치를 처리하는 반면 DataFrame은 '문자열', '수치' 등 다양한 데이터형을 다룹니다. Matrix는 행이든 열이든 모두 의미가 있을 수 있지만 DataFrame은 주로 열에 대해서 의미가 있습니다.
다음과 같이 일차원 벡터를 만들 수 있습니다.
b = np.array(list(range(8)))
b
이를 이차원의 매트릭스로 만들려면 단순히 shape 값만 바꿔주면 됩니다.
b.reshape((2, 4))
2x4 매트릭스가 만들어졌습니다. 행이 2이고, 열이 4입니다. 이처럼 (2, 4)를 numpy에선 shape라 부르고 reshape() 함수를 이용하면 행렬의 구조를 바꿀 수 있습니다. 삼차원도 가능합니다.
b.reshape((4, 2))
b.reshape((2, 2, 2))

shape의 값을 바꿔주는 것만으로 매트릭스 구조를 쉽게 바꿀 수 있습니다. 이런 유연함이 ndarray형의 특징입니다. 다음과 같이 0으로 채워진 매트릭스도 만들 수 있습니다. 물론 다른 숫자도 가능하고, 대각선으로만 1을 넣어 만들 수 있습니다.
np.zeros((2, 4))
np.full((2, 4), 7)
np.eye(3)


직접 한 번에 만들 수도 있습니다.
b = np.array([[0, 1, 2], [3, 4, 5]])
b
numpy는 매트릭스를 다루기 때문에 매트릭스 연산을 할 수 있습니다. 벡터(ndarray)를 만들어서 해보도록 하겠습니다.
a = np.array(list(range(1, 10)))
b = np.array(list(range(11, 20)))
a = a.reshape(3, 3)
b = b.reshape(3, 3)
a + b
빼기, 곱하기, 나누기 모두 가능합니다. 곱하기 경우 요소기리 곱하는 경우 외 행렬곱이라는 계산 방법이 있습니다. 이런 경우엔 dot() 메소드를 사용합니다.

numpy에는 np.matrix() 함수가 있습니다. 이 함수로 matrix를 만들면 지금까지 살펴본 데이터형과 다른 데이터형이 만들어집니다. numpy에서는 ndarray와 matrix 데이터형 두 가지가 있으며 서로 사용 방법이 다릅니다. 우선 ndarray에 충분히 익숙해지도록 합시다.
나머지 matplotlib 패키지는 다음 글에서 다뤄보겠습니다.
이상 데이터 분석을 위한 삼위일체 (1) 였습니다. ^_^
'Machine, Deep Learning > Machine, Deep Learning 실습' 카테고리의 다른 글
| Context Switch란? (0) | 2019.06.18 |
|---|---|
| 데이터 분석을 위한 삼위일체 (2) (0) | 2019.06.17 |
| Kaggle - 남은 주차공간을 알려주는 AI (1) | 2019.06.15 |
| Kaggle - Heart Disease Dataset (2) (2) | 2019.06.15 |
| Kaggle - Heart Disease Dataset (1) (0) | 2019.06.14 |


