본 글은 Kaggle Find a Car Park에서 Data를 얻어왔으며, Youtube 빵형의 개발도상국 채널의 '남은 주차공간을 알려주는 인공지능 - Python, Deep Learning'을 참고하여 작성한 글입니다.
https://www.kaggle.com/daggysheep/find-a-car-park/downloads/find-a-car-park.zip/1
Kaggle: Your Home for Data Science
www.kaggle.com
본 글에선 자신의 집 앞에 주차 공간이 비어있는지, 꽉 차 있는지 알려주는 인공지능을 구현해 볼 것입니다. 주차장 사진에서 모델이 어느 부분에 주차장이 비어 있다고 생각하는지를 시각화하여 나타내는 것을 구현할 것입니다.
저희가 가져온 데이터 셋은 2가지의 Labels가 있습니다. "full"과 "free"인데요 "full"이면 꽉 찬 것이고, "free"이면 비어있는 것입니다. 설명이 된 부분을 보면 집에 왔을 때 주차장이 비어있는지 않는지를 알고 싶지 않냐고 물어보고 있습니다. 라즈베리 파이를 이용해서 여유 공간이 있는지 여부를 식별하고, 사용자에게 메시지로 이미지를 보냈다고 합니다.

데이터 셋은 총 3기가입니다. 상당히 크네요. 이 데이터를 받아와서 보도록 할텐데 우선 라이브러리를 가져오도록 하겠습니다.
import os, glob
import scipy
import numpy as np
import matplotlib.pyplot as plt
from keras.preprocessing.image import ImageDataGenerator, load_img, img_to_array
from keras.applications.mobilenet_v2 import MobileNetV2, preprocess_input
from keras.layers import GlobalAveragePooling2D, Dense
from keras.models import Model, load_model
from keras.callbacks import ModelCheckpoint라이브러리를 받아왔으면 이제 DataSet을 보도록 합시다.
BASE_PATH = 'data'
full_list = glob.glob(os.path.join(BASE_PATH, 'Full/*.jpg')) # Full Parking lot
free_list = glob.glob(os.path.join(BASE_PATH, 'Free/*.jpg')) # Free Parking lot
# To see the first image
plt.figure(figsize=(16, 16))
plt.subplot(1, 2, 1)
plt.title(len(full_list))
plt.imshow(full_img)
plt.subplot(1, 2, 2)
plt.title(len(free_list))
plt.imshow(free_img)
보시다시피 "full" image는 차가 가득차있고, "free"에는 여분의 주차 공간이 있네요. 저희가 title에 총 이미지 배열(Array)를 세어봤는데, "full" images는 2195 장이고, "free" images는 1067장이네요. 단, Labeling이 주차 공간이 비어있는 것만 나타낼 뿐 어느 위치의 공간이 비어있는지는 Labeling이 되어 있진 않습니다.
저희는 Feature activation map을 통해서 어느 공간이 비어있는지를 시각화 해보겠습니다.
Data Generator를 작성해보도록 하겠습니다.
그 전에 Generator가 무엇일까요? Generator를 알기 위해선, Iterator를 알고 가야합니다.
1. Iterator
Python에서 List, Set, Dictionary와 같은 컬렉션이나 문자열과 같은 문자 Sequence 등들은 for 문을 써서 하나씩 데이터를 처리할 수 있는데, 이렇게 하나 하나 처리할 수 있는 컬렉션이나 Sequence 들을 Iterable 객체 (Iterable Object)라 부릅니다.
# List Iterable
for n in [1, 2, 3, 4, 5]:
print(n)
# 문자열 Iterable
for c in "Hello World":
print(c)
2. Generator
Generator는 Iterator의 특수한 형태입니다. Generator 함수는 함수 안에 yield를 사용하여 데이터를 하나씩 리턴하는 함수입니다. Generator 함수가 처음 호출되면, 그 함수 실행 중 처음으로 만나는 yield에서 값을 리턴합니다. Generator 함수가 다시 호출되면, 직전에 실행된 yield 문 다음부터 다음 yield 문을 만날 때까지 문장들을 실행하게 됩니다. 이러한 Generator 함수를 변수에 할당하면 그 변수는 Generator 클래스 객체가 됩니다.
# Generator 함수
def gen():
yield 1
yield 2
yield 3
# Generator 객체
g = gen()
print(type(g)) # <class 'generator'>
# next() 함수 사용
n = next(g); print(n) # 1
n = next(g); print(n) # 2
n = next(g); print(n) # 3
# for 루프 사용 가능
for x in get():
print(x)List나 Set과 같은 컬렉션에 대한 iterator는 해당 컬렉션이 이미 모든 값을 가지고 있는 경우이나, Generator는 모든 데이터를 갖지 않은 상태에서 yield에 의해 하나씩만 데이터를 만들어 가져온다는 차이점이 있습니다. 이러한 Generator는 데이터가 무제한이어서 모든 데이터를 리턴할 수 없을 때, 데이터가 대량이어서 일부씩 처리하는 것이 필요한 경우, 혹은 모든 데이터를 계산하면 속도가 느려서 그 때마다 On Demand로 처리하는 것이 좋은 경우에 사용됩니다.
train_datagen = ImageDataGenerator(
rotation_range = 10,
width_shift_range = 0.1,
height_shift_range = 0.1,
brightness_range = [0.8, 1.2],
shear_range = 0.01,
zoom_range = [0.9, 1.1],
validation_split = 0.1, # 10%의 데이터를 validation_split으로 사용하겠단 뜻입니다.
# 그럼 나머지 90%가 학습용이 되겠죠.
preprocessing_function = preprocess_input
)
val_datagen = ImageDataGenerator(
validation_split = 0.1,
preprocessing_function = preprocess_input
)preprocess_input은 keras.applications.mobilenet_v2 import MobileNetV2, preprocess_input에서 가져와서 사용합니다. MobileNetV2에 인풋으로 사용하기 전에 전 처리하는 코드가 preprocess_input으로 함수화 되어 있습니다. 따라서 그대로 사용하시면 됩니다.
즉, preprocess_input을 import 해주고 ImageDataGenerator에 preprocessing_function에 넣어주기만 하면 됩니다.
그 다음 validation datagenerator는 validation_split을 0.1로 똑같이 정해주고, preprocessing_function을 지정해줍니다. validation datagenerator는 위에서 했던 것을 해줄 필요가 없습니다.
다음은 flow_from_directory를 사용해서 directory에 있는 데이터를 모두 불러 올 것입니다.
train_gen = train_datagen.flow_from_directory(
BASE_PATH,
target_size = (224, 224),
classes = ['Full', 'Free'],
class_mode = 'categorical',
batch_size = 32,
shuffle = True,
subset = 'training'
)
val_gen = val_datagen.flow_from_directory(
BASE_PATH,
target_size = (224, 224),
classes = ['Full', 'Free'],
class_mode = 'categorical',
batch_size = 32,
shuffle = False,
subset = 'validation'
)이미지는 모바일에 넣어야 되니까 (224, 224) 사이즈로 리사이징을 했습니다. classes에는 "Full", "Free"로 지정해줍시다. class_mode는 "Categorical"로 지정을 해주면서 "Full"인 경우엔 [1, 0], "Free"인 경우엔 [0, 1]로 표현됩니다.
batch_size는 32, training data는 shuffle을 "True"로 해주고 subset으로 "training"이라고 알려 줍시다.
validation generator는 거의 다 똑같지만, shuffle을 "False"로 했고 subset을 "validation"으로 지정해주면 됩니다.
위 코드를 실행하면 위와 같이 뜹니다.

training datas는 2937, validation datas는 325 / 클래스는 둘 다 2개 ("Full", "Free")로 구성되어 있습니다.
print(val_gen.class_indices) # {'Full':0, 'Free':1}그래서 validation generator의 indices를 보면 클래스가 2개로 구성됨을 볼 수 있습니다.
Transfer Learning을 위해서 Model을 정의해보도록 하겠습니다.
여기서 잠깐 Transfer Learning이 무엇일까요??
Transfer Learning
기존의 만들어진 모델을 사용하여 새로운 모델을 만들시 학습을 빠르게 하며, 예측을 더 높이는 방법입니다. 실질적으로 Convolution network을 처음부터 학습시키는 일은 많지 않습니다. 대부분의 문제는 이미 학습된 모델을 사용해서 문제를 해결할 수 있습니다. 결론적으로 이미 잘 훈련된 모델이 있고, 특히 모델과 유사한 문제를 해결시 Transfer Learning을 사용합니다.
저희는 4가지 경우가 있습니다.
| 훈련 데이터 少, Original 데이터와 유사 | 데이터의 양이 적어서 fine-tune(전체 모델에 대해서 역전파를 진행하는 것)은 over-fitting의 위험이 있기에 하지 않습니다. |
| 훈련 데이터 多, Original 데이터와 유사 | 새로 학습할 데이터의 양이 많은 것은 over-fitting의 위험이 낮다는 뜻이므로, 전체 레이어에 대해서 fine-tune을 합니다. |
| 훈련 데이터 少, Original 데이터와 다름 | 데이터의 양이 적기 때문에 최종 단계의 linear classifier 레이어를 학습하는 것이 좋습니다. 반면 데이터가 서로 다기 때문에 마지막 부분(the top of the network)만 학습하는 것은 좋지 않습니다. 네트워크 초기 부분 어딘가 activation 이후에 특정 레이어를 학습시키는게 좋습니다. |
| 훈련 데이터 多, Original 데이터와 다름 | 데이터가 많기에 ConvNet을 새로 만들 수 있지만, transfer learning이 더 효율이 좋습니다. 전체 네트워크에 대해 fine-tune을 해도 됩니다. |
base_model = MobileNetV2(input_shape=(224, 224, 3), weights='imagenet', include_top=False)
x = base_model.output
x = GlobalAveragePooling2D()(x)
output = Dense(2, activation='softmax')(x)
model = Model(inputs=base_model.input, outputs=output)
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['acc'])
model.summary()저희는 MobileNetV2를 쓸 것이고, input_shape는 (224, 224, 3)입니다. (3은 rgb값이라서 3입니다. 흑백일 경우엔 1입니다) 이미 학습된 모델을 가지고 내가 원하는 모델로 개조하는 작업을 transfer learning이라고 하는데, 이 때문에 weights를 'imagenet'으로 설정했습니다. include_top은 output을 직접 정의할 것이라서 False로 설정합니다.
base_model의 output을 x에 넣어줍니다. 그리고 1차원으로 데이터를 펴주기 위해서 GlobalAveragePooling2D()(x)를 실행합니다. 그리고 마지막 output은 2개인데, 왜 2개이냐면 "full"일 땐 [1, 0], "free"일 땐 [0, 1] 나오게 해야 되서 입니다.
그 다음은 model을 정의해주고 컴파일 해줍니다. 0에서 1사이로 정확도가 나오도록 출력할 것입니다.

input은 (224, 224, 3)이 들어가고 Convolution을 거쳐서 마지막 output을 보시면 1280이 나옵니다.

그리고 마지막에 2개의 output을 뱉어냅니다. 그 다음 혹시 모르니까 모델에 trainable을 True로 설정해줍니다.
for layer in model.layers:
layer.trainable = True이걸 False로 해주면 Layer의 Weight가 학습을 실행해도 변하지 않습니다. 원래는 거의다 True로 되어 있는데, 가끔씩 안되어 있는 model이 있습니다. 혹시 모르니 한번씩 해줍니다.
이제 train을 시키는데, fit_generator로 트레이닝을 시킵니다.
history = model.fit_generator(
train_gen,
validation_data = val_gen,
epochs = 10,
steps_per_epoch = len(train_gen) / 32, # 32 is the batch_size
validation_steps = len(val_gen) / 32,
callbacks = [
ModelCheckpoint('model.h5', monitor = 'val_acc', save_best_only = True, verbose = 1)
]
)반복 학습 폭은 10번을 지정해줍니다. 가장 accuarcy가 높은거 하나만 model.h5로 저장해라는 코드를 짰습니다. 학습을 시켜보니 에러가 떴습니다.
'`validation_steps=None` is only valid for a generator based on the `keras.utils.Sequence` class. Please specify `validation_steps` or use the `keras.utils.Sequence` class.'
'`steps_per_epoch=None` is only valid for a generator based on the `keras.utils.Sequence` class. Please specify `steps_per_epoch` or use the `keras.utils.Sequence` class.'
위 두가지 에러가 떴습니다. 위 에러는 keras 2.2.4에서 일어나는 에러라고 합니다. 따라서 kears.utils.Sequence 클래스로 모델을 지정해야하는데, 저희는 그러지 않았습니다. 그래서 validation_steps, steps_per_epoch를 우리가 직접 지정해주도록 합시다. 각각 길이에 batch_size를 나누어서 설정을 해줬습니다.

이제 새로운 모델을 만들 것입니다.
model = load_model('model.h5')
last_weight = model.layers[-1].get_weights()[0] # (1280, 2)
new_model = Model(
inputs = model.input,
outputs = (
model.layers[-3].output, # the layer just before GAP, for using spatial features
model.layers[-1].output
)
)
new_model.summary()model을 저장한 것을 load 해줍니다. activation map을 그려야하니까 model의 마지막 weight를 불러옵니다. model의 마지막 레이어에 weight를 불러온다는 것입니다. (차원수는 1280에 2가됩니다. 왜냐면 1280에 2를 곱해주는 부분이라 그렇습니다.)
마지막 Dense layer와 위의 1280이 혼합된 1280 x 2 행렬이 만들어지는 것입니다.
그리고 우리가 새로운 모델을 하나 정의했는데, 우리가 학습시킨 모델과 다 똑같은데 다른 점은 output이 2개인 점입니다. 'model.layers[-1].ouput'의 output 2개짜리 하나랑 'model.layers[-3].output' 이거는 Global Average Pooling 전 activation까지 한 layer를 outpt으로 하는 새로운 모델을 만들었습니다. 즉, 위 사진에서 out_relu(ReLU) 레이어랑 dense_1 레이어를 출력으로 삼는다는 뜻입니다.
왜 굳이 out_relu(ReLU)로 개선을 하나면 Convolution Layer까지가 Spatial Feautres을 가지고 있어서 그렇습니다. 근데 Global Average Pooling을 통과하게 되면, 이런 Spatial Features가 사라지게 됩니다. 공간적인 특징을 가진 레이어를 사용하지 못하게 됩니다.
위의 코드를 실행하면 이전과 똑같습니다. 단, output이 2개일 뿐입니다.

그리고 이제 새로운 데이터를 넣어서 주차공간이 비어있는지 안 비어있는지를 확인해봅시다.
'''
Free/img_129142058.jpg
Free/img_129173058.jpg
Free/img_724143006.jpg
Full/img_127115558.jpg
Full/img_127055603.jpg
'''
test_img = img_to_array(load_img(os.path.join(BASE_PATH, 'Free/img_129173058.jpg'), target_size=(224, 224)))
test_input = preprocess_input(np.expand_dims(test_img.copy(), axis=0))
pred = model.predict(test_input)
plt.figure(figsize=(8, 8))
plt.title('%.2f%% Free' % (pred[0][1] * 100))
plt.imshow(test_img.astype(np.uint8))test image를 한 장 불러와서 preprocess를 해준 다음 model.predict를 해주면 주차장이 비어있는지 차 있는지를 알 수 있습니다. 코드를 돌려보니

98.98%로 비어있는 확률을 냈습니다. 어디가 비었는지는 안 알려주죠?
그렇다면 어째서 이 모델이 비었다고 판단하는지를 알아내는 코드를 짜보도록 하겠습니다.
last_conv_output, pred = new_model.predict(test_input)
last_conv_output = np.squeeze(last_conv_output) # (7, 7, 1280)
feature_activation_maps = scipy.ndimage.zoom(last_conv_output, (32, 32, 1), order=1) # (7, 7, 1280) => (224, 224, 1280)
pred_class = np.argmax(pred) # 0: Full, 1: Free
predicted_class_weights = last_weight[:, pred_class] # (1280, 1)
final_output = np.dot(feature_activation_maps.reshape((224*224, 1280)), predicted_class_weights).reshape((224, 224)) # (224*224, 1280) dot_produt (1280, 1) = (224*224, 1)
plt.imshow(final_output, cmap='jet')이번엔 new_model을 사용할 것입니다. 아까랑 똑같은 input을 넣어주고, new_model 같은 경우엔 output이 2개가 나오는데 그래서 마지막 Convolution output하고 우리가 만든 원래 모델의 output을 2개 받을 것입니다. 그래서 마지막 Convolution output을 squeeze를 통해서 (7, 7, 1280)로 만들었습니다. 얘는 global Average Pooling을 통과 하기전 사이즈입니다.
근데 저희의 원래 이미지는 (224, 224) 입니다. 그래서 확대를 시킬 예정입니다. scipy.ndimage.zoom을 사용해서 32배를 확대시키면 (7, 7, 1280)이 (224, 224, 1280)이 됩니다. 그리고 이것을 feature_activation_maps에 저장합니다.
그 다음으로 우리가 예측한 class를 argmax를 통해서 알아냅니다. 그래서 가득 찼으면 0, 비어있으면 1이 나옵니다. 지금같으면 1로 나오겠죠? 그리고 아까 뽑아놨던 Dense layer의 weight에서 클래스 인덱스의 weight만을 뽑아줍니다. 그리고 feature_activation_maps와 predicted_class_weights를 곱해줄 것입니다.
왜 이렇게 하냐면 Global Average Pooling을 건너뛰기 위함입니다. 위에서 Global Average Pooling을 하면 Spacial features가 없어진다고 했습니다. 그래서 마지막 Convolution Layer에서 나온 값에서 확대해서 (224, 224, 1280)짜리 features map이 나옵니다. 이거랑 (1280, 1)짜리를 곱하는 것입니다. 이렇게 하면 (224, 224) 이미지가 나옵니다. 단, 이거를 그냥 곱하는 것이 아니라 (224, 224, 1280)에서의 (224, 224)를 reshape을 할 것입니다. 즉, 224*224 = 50126이기에 (50126, 1280)과 (1280, 1)을 dot product를 통해서 (224, 224)만 남는 것입니다.
얘를 출력하면 Activation map이 출력됩니다.
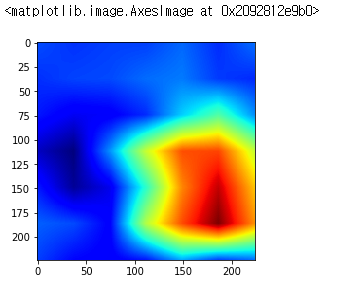
자, 이제 마지막으로 결과물을 출력하는 일만 남았습니다.
fig, ax = plt.subplots(nrows=1, ncols=2)
fig.set_size_inches(16, 20)
ax[0].imshow(test_img.astype(np.uint8))
ax[0].set_title('image')
ax[0].axis('off')
ax[1].imshow(test_img.astype(np.uint8), alpha=0.5)
ax[1].imshow(final_output, cmap='jet', alpha=0.5)
ax[1].set_title('class activation map')
ax[1].axis('off')
plt.show()
원래 이미지는 왼쪽인데, 오른쪽 이미지에서 빨간색 부분으로 활성화된 부분이 있습니다. 이 부분을 집중적으로 보고서 주차장이 비어있구나를 판단함을 알 수 있었습니다. 이런 식으로 Activation Map을 통해서 모델이 어떤 부분을 보고서 이런 예측을 했는지 알아낼 수 있습니다.
그렇다면 이 모델이 어떻게 주차장 지역만을 골라서 확인할 수 있었을까요? 분명 도로 부분도 비어있는데 말이죠? 이 질문에 대한 답은 바로 Dataset에 있습니다. 이 Dataset에선 "Full"과 "Free"의 이미지들간의 차이가 도로가 아닌 주차공간에만 있기 때문입니다. 만약 도로쪽에도 차가 있었다 없었다고 한다면 도로에도 붉은 색이 나올 수 있겠죠 !
이상 Kaggle - 남은 주차공간을 알려주는 AI 였습니다. ^_^
'Machine, Deep Learning > Machine, Deep Learning 실습' 카테고리의 다른 글
| 데이터 분석을 위한 삼위일체 (2) (0) | 2019.06.17 |
|---|---|
| 데이터 분석을 위한 삼위일체 (1) (0) | 2019.06.16 |
| Kaggle - Heart Disease Dataset (2) (2) | 2019.06.15 |
| Kaggle - Heart Disease Dataset (1) (0) | 2019.06.14 |
| Kaggle - MINST 예측 모델 생성 by Keras (2) (2) | 2019.06.10 |



