Python 데이터 분석 패키지 삼위일체를 알아보는 시간을 가졌었는데, 지금까지 pandas와 numpy를 알아봤습니다. 지금 이 시간엔 matplotlib를 알아볼 것입니다.
주로 Python에서 시각화를 담당하는 matplotib는 pandas와 조화를 이루면서 그 기능을 최고로 발휘 할 수 있습니다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inlinedf = pd.read_csv("input/input.csv")
df.plot()
plt.show()
역시나 이전에 사용했던 'Kaggle Titanic Data'를 이용하도록 하겠습니다. 단순히 DataFrame 객체를 만들고 메서드인 plot() 함수를 실행하는 것만으로 그림이 그려졌습니다. 이미 DataFrame 객체에는 matplotlib를 이용해 그래프를 그리는 메서드가 이미 있습니다. 그래서 matplotlib 객체를 따로 만들지 않아도 됩니다. 그리고 plt.show() 같은 경우엔 Pycharm을 사용하는 경우 항상 넣어야하는 문장이니 기억해야 합니다. (Jupyter Notebook 같은 경우엔 그래프를 자동으로 보여줍니다)
df2 = df.Age # hp 변수를 df2에 저장
df2.plot()
단순하게 DataFrame의 변수 하나만 따로 저장한 후 plot() 함수를 실행했습니다. 사실 따로 저장하지 않고 df.Age.plot() 함수를 사용해도 무방합니다. 명령어 중 plt.figure() 함수는 새로운 그래프를 그리겠다는 명령어입니다. 이 명령어가 없다면 기존 그래프에 겹쳐서 그려지게 됩니다. 이 또한 plt.figure()와 plt.show()는 Jupyter에선 생략해도 됩니다.
df2 = df[['Age', 'Fare']]
df2.plot()
음.. 사실 데이터가 좀 크다보니 그래프가 지저분하게 그려지는 부분이 있습니다. 그래도 우리는 그려보는데 의의를 가지도록 합시다. 이제 인자 하나를 추가해서 막대 그래프로 그려봅시다.
df2.plot(kind="bar")
ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ 그려보니 이렇게 됐습니다. 앞서 말했듯이 그려보는데 의의를 둡시다. df2.plot.bar() 명령어로 똑같은 그래프를 그릴 수 있습니다. 둘 중 편한걸 그리시면 됩니다.
참고로 df2.plot.을 입력한 후 "Tab"키를 누르면 사용 가능한 그래프 목록이 나옵니다. 이 중 원하는 것을 사용하면됩니다. 이젠 pandas의 DataFrame 객체 메서드가 아닌 matplotlib의 함수를 바로 실행해 그래프를 그려볼까요?
plt.plot(np.arange(len(df.Fare)),df.Fare)
plt 네임스페이스를 통해 관련된 함수를 실행했습니다. 행이 "len(df.Fare)"이고 열이 "df.Fare"입니다. 결국, 두 가지 방식으로 matplotlib를 사용한 것이었습니다. 객체.plot() / plt.plot(객체 변수) 막대 그래프에는 몇 가지 옵션이 있습니다. 먼저 누락된 막대 그래프를 그려봅시다.
df2.plot.bar(stacked=True)
ㅋㅋㅋㅋ 데이터가 너무 많아서 이렇게 됐네요. 원래는 이렇게 되어야 합니다.
가로 모드를 사용해볼까요?
df2.plot.barh(stacked=True)
히스토그램 그리기
df1 = df.Age
df1.plot.hist()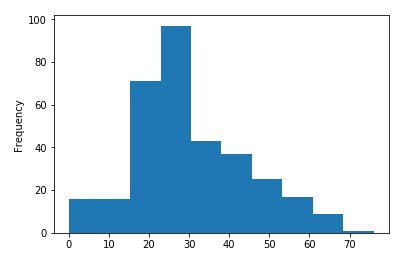
한 변수에 대해 히스토그램을 그리면 y축은 자연스럽게 빈도수가 됩니다. x축은 알맞게 구간이 설정되고 그 안에 속한 데이터를 카운팅 합니다. 만약 간격을 조절하고 싶다면 bins 인자를 추가하면 됩니다.
df1.plot.hist(bins=20)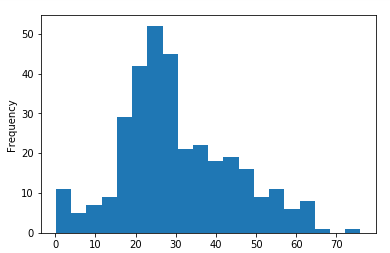
만약 두 변수가 DataFrame에 있다면 함께 나타납니다. 이 때 겹치는 부분이 있으니 투명도를 조절하는 것이 좋습니다.
df2.plot.hist(alpha=0.6)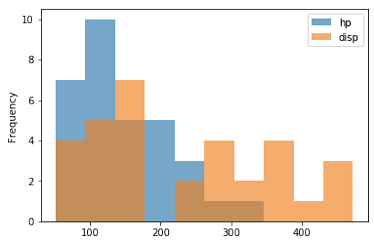
Box Plot 그리기
Box Plot은 중앙값, IQR, 아웃라이어 등 데이터의 특징을 모두 나타냅니다. Box Plot은 두 가지 방법으로 그릴 수 있습니다.
df2.boxplot()
df2.plot.box()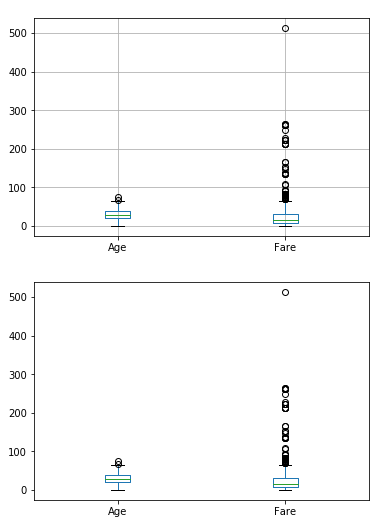
차이점이 크진 않으니 boxplot() 함수는 그룹을 지어 그릴 수 있도록 지원합니다.
df3 = df[['Age', 'Fare', 'Pclass']]
df3.boxplot(by='am')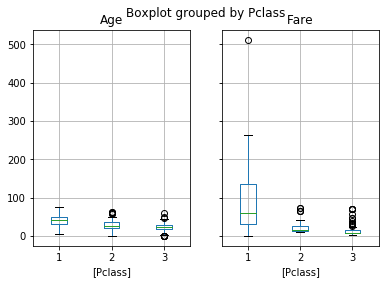
Pclass 변수는 선실의 클래스를 나타내는 변수로서 1, 2, 3으로 이루어져 있습니다. 이 세가지 경우에 대해 각각을 그래프에서 나타내 줍니다.
산점도 그리기
산점도는 두 변수 간의 상관관계를 보기 위해 그리는데 그리는 방법은 다음과 같습니다.
df3.plot.scatter(x='Age', y='Fare')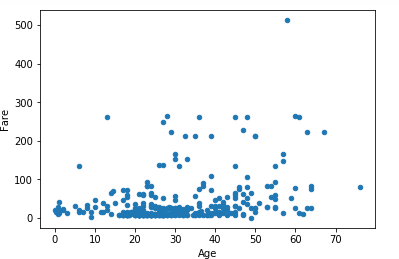
원의 크기와 투명도도 조절이 가능합니다.
df3.plot.scatter(x='Age', y='Fare', s=100, alpha=0.5)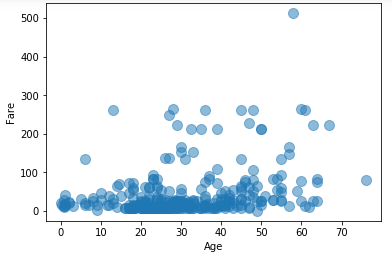
pandas 패키지에는 DataFrame의 모든 변수에 대한 산점도를 한 번에 보여주는 함수가 있습니다.
from pandas.plotting import scatter_matrix
scatter_matrix(df, alpha=0.4, figsize=(12, 12), diagonal='kde')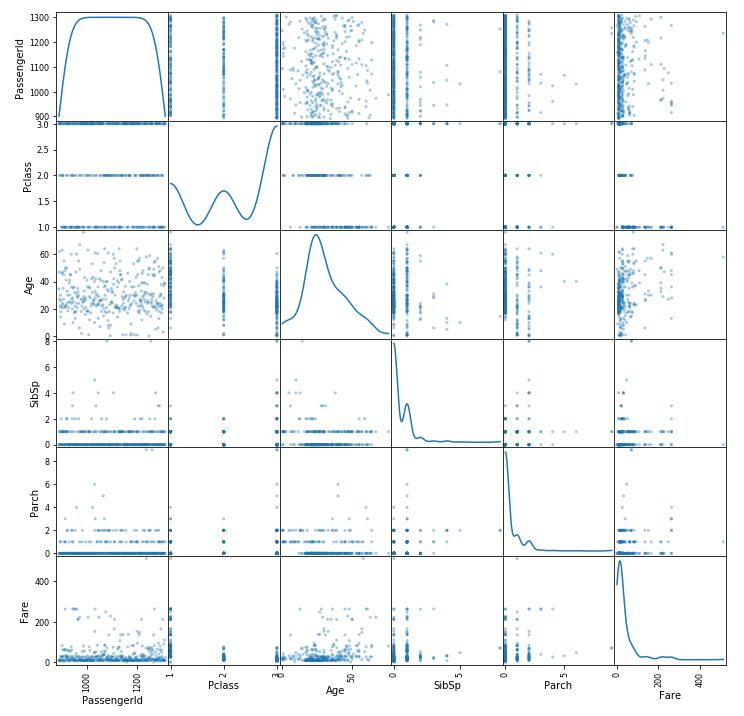
모든 변수를 x축과 y축에 나열되고 서로 만나는 지점에 두 변수 간의 산점도를 보여줍니다. 대각선 부분은 X축 Y축 모두 자기 자신이기 때문에 자신의 값을 그대로 보여줍니다.
이상 데이터 분석을 위한 삼위일체 (2) 였습니다. ^_^
'Machine, Deep Learning > Machine, Deep Learning 실습' 카테고리의 다른 글
| Numpy 배열 생성하기 (0) | 2019.06.24 |
|---|---|
| Context Switch란? (0) | 2019.06.18 |
| 데이터 분석을 위한 삼위일체 (1) (0) | 2019.06.16 |
| Kaggle - 남은 주차공간을 알려주는 AI (1) | 2019.06.15 |
| Kaggle - Heart Disease Dataset (2) (2) | 2019.06.15 |

